前言:
模拟学生成绩信息写入es数据库,包括姓名、性别、科目、成绩。
示例代码1:【一次性写入10000*1000条数据】 【本人亲测耗时5100秒】
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import random
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十']
sexs = ['男', '女']
subjects = ['语文', '数学', '英语', '生物', '地理']
grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86]
datas = []
start = time.time()
# 开始批量写入es数据库
# 批量写入数据
for j in range(1000):
print(j)
action = [
{
"_index": "grade",
"_type": "doc",
"_id": i,
"_source": {
"id": i,
"name": random.choice(names),
"sex": random.choice(sexs),
"subject": random.choice(subjects),
"grade": random.choice(grades)
}
} for i in range(10000 * j, 10000 * j + 10000)
]
helpers.bulk(es, action)
end = time.time()
print('花费时间:', end - start)elasticsearch-head中显示:
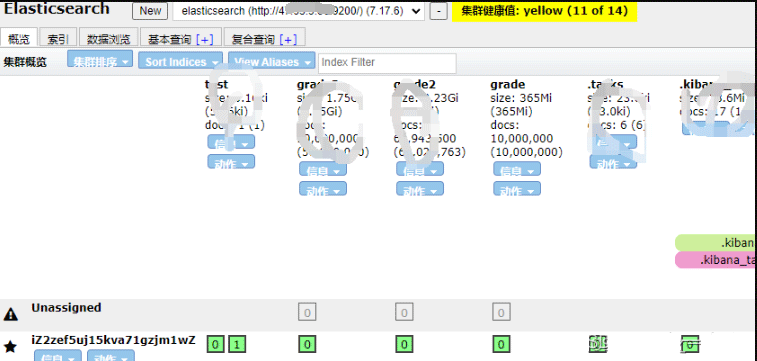
示例代码2:【一次性写入10000*5000条数据】 【本人亲测耗时23000秒】
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import random
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# print(es)
names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十']
sexs = ['男', '女']
subjects = ['语文', '数学', '英语', '生物', '地理']
grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86]
datas = []
start = time.time()
# 开始批量写入es数据库
# 批量写入数据
for j in range(5000):
print(j)
action = [
{
"_index": "grade3",
"_type": "doc",
"_id": i,
"_source": {
"id": i,
"name": random.choice(names),
"sex": random.choice(sexs),
"subject": random.choice(subjects),
"grade": random.choice(grades)
}
} for i in range(10000 * j, 10000 * j + 10000)
]
helpers.bulk(es, action)
end = time.time()
print('花费时间:', end - start)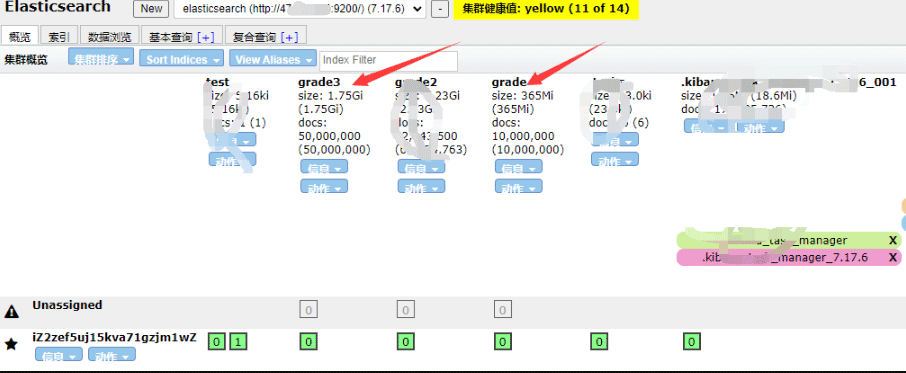
示例代码3:【一次性写入10000*9205条数据】 【耗时过长】
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import random
import time
es = Elasticsearch(hosts='http://127.0.0.1:9200')
names = ['刘一', '陈二', '张三', '李四', '王五', '赵六', '孙七', '周八', '吴九', '郑十']
sexs = ['男', '女']
subjects = ['语文', '数学', '英语', '生物', '地理']
grades = [85, 77, 96, 74, 85, 69, 84, 59, 67, 69, 86, 96, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86]
datas = []
start = time.time()
# 开始批量写入es数据库
# 批量写入数据
for j in range(9205):
print(j)
action = [
{
"_index": "grade2",
"_type": "doc",
"_id": i,
"_source": {
"id": i,
"name": random.choice(names),
"sex": random.choice(sexs),
"subject": random.choice(subjects),
"grade": random.choice(grades)
}
} for i in range(10000*j, 10000*j+10000)
]
helpers.bulk(es, action)
end = time.time()
print('花费时间:', end - start)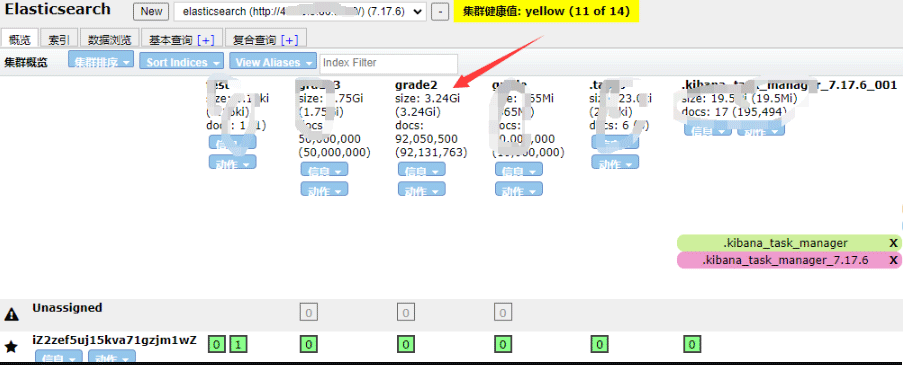
查询数据并计算各种方式的成绩总分。
示例代码4:【一次性获取所有的数据,在程序中分别计算所耗的时间】
from elasticsearch import Elasticsearch
import time
def search_data(es, size=10):
query = {
"query": {
"match_all": {}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
if __name__ == '__main__':
start = time.time()
es = Elasticsearch(hosts='http://192.168.1.1:9200')
# print(es)
size = 10000
res = search_data(es, size)
# print(type(res))
# total = res['hits']['total']['value']
# print(total)
all_source = []
for i in range(size):
source = res['hits']['hits'][i]['_source']
all_source.append(source)
# print(source)
# 统计查询出来的所有学生的所有课程的所有成绩的总成绩
start1 = time.time()
all_grade = 0
for data in all_source:
all_grade += int(data['grade'])
print('所有学生总成绩之和:', all_grade)
end1 = time.time()
print("耗时:", end1 - start1)
# 统计查询出来的每个学生的所有课程的所有成绩的总成绩
start2 = time.time()
names1 = []
all_name_grade = {}
for data in all_source:
if data['name'] in names1:
all_name_grade[data['name']] += data['grade']
else:
names1.append(data['name'])
all_name_grade[data['name']] = data['grade']
print(all_name_grade)
end2 = time.time()
print("耗时:", end2 - start2)
# 统计查询出来的每个学生的每门课程的所有成绩的总成绩
start3 = time.time()
names2 = []
subjects = []
all_name_all_subject_grade = {}
for data in all_source:
if data['name'] in names2:
if all_name_all_subject_grade[data['name']].get(data['subject']):
all_name_all_subject_grade[data['name']][data['subject']] += data['grade']
else:
all_name_all_subject_grade[data['name']][data['subject']] = data['grade']
else:
names2.append(data['name'])
all_name_all_subject_grade[data['name']] = {}
all_name_all_subject_grade[data['name']][data['subject']] = data['grade']
print(all_name_all_subject_grade)
end3 = time.time()
print("耗时:", end3 - start3)
end = time.time()
print('总耗时:', end - start)运行结果:

在示例代码4中当把size由10000改为 2000000时,运行效果如下所示:
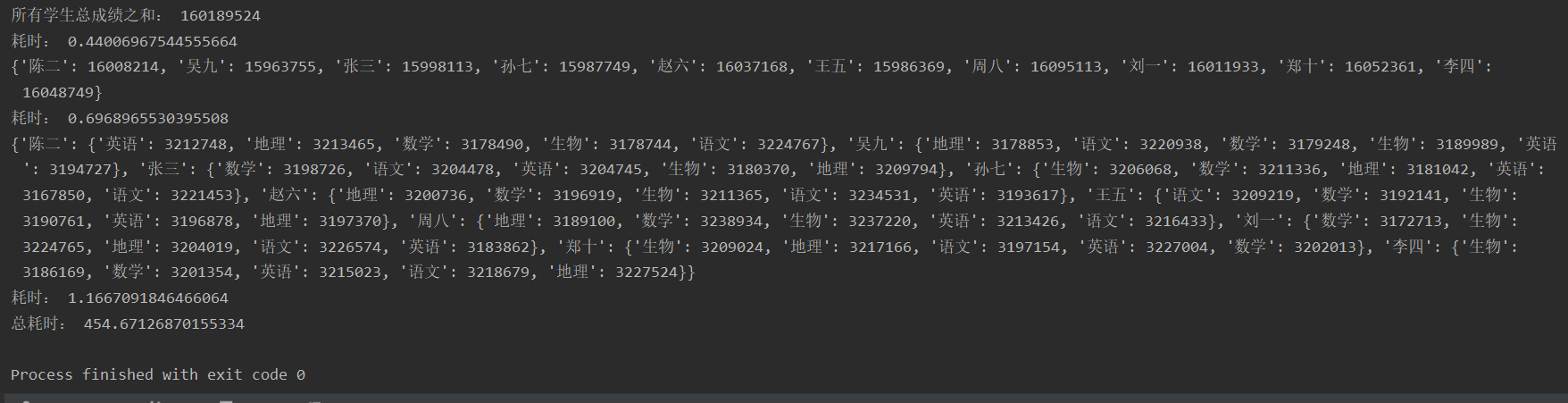
在项目中一般不用上述代码4中所统计成绩的方法,面对大量的数据是比较耗时的,要使用es中的聚合查询。计算数据中所有成绩之和。
示例代码5:【使用普通计算方法和聚类方法做对比验证】
from elasticsearch import Elasticsearch
import time
def search_data(es, size=10):
query = {
"query": {
"match_all": {}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
def search_data2(es, size=10):
query = {
"aggs": {
"all_grade": {
"terms": {
"field": "grade",
"size": 1000
}
}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
if __name__ == '__main__':
start = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
size = 2000000
res = search_data(es, size)
all_source = []
for i in range(size):
source = res['hits']['hits'][i]['_source']
all_source.append(source)
# print(source)
# 统计查询出来的所有学生的所有课程的所有成绩的总成绩
start1 = time.time()
all_grade = 0
for data in all_source:
all_grade += int(data['grade'])
print('200万数据所有学生总成绩之和:', all_grade)
end1 = time.time()
print("耗时:", end1 - start1)
end = time.time()
print('200万数据总耗时:', end - start)
# 聚合操作
start_aggs = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
# size = 2000000
size = 0
res = search_data2(es, size)
# print(res)
aggs = res['aggregations']['all_grade']['buckets']
print(aggs)
sum = 0
for agg in aggs:
sum += (agg['key'] * agg['doc_count'])
print('1000万数据总成绩之和:', sum)
end_aggs = time.time()
print('1000万数据总耗时:', end_aggs - start_aggs)运行结果:
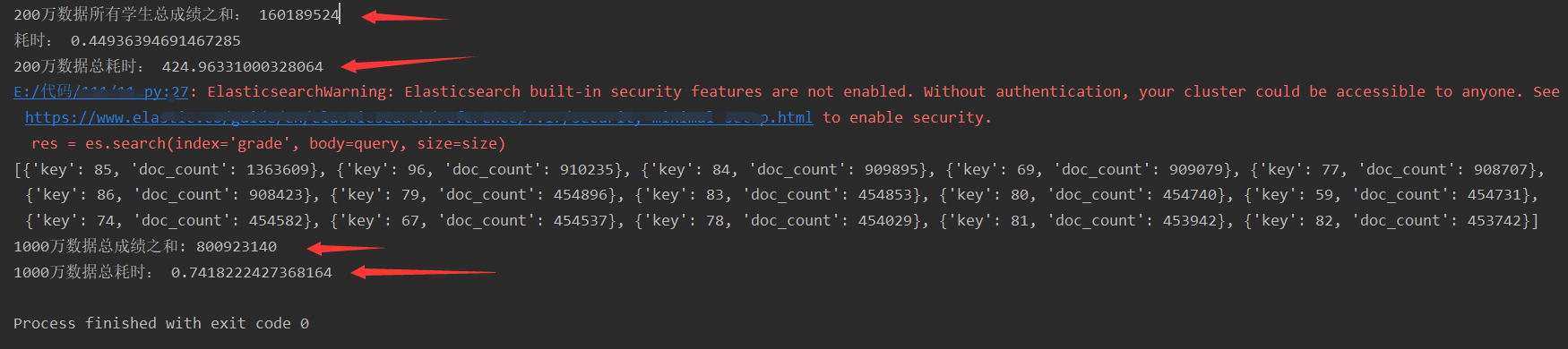
计算数据中每个同学的各科总成绩之和。
示例代码6: 【子聚合】【先分组,再计算】
from elasticsearch import Elasticsearch
import time
def search_data(es, size=10):
query = {
"query": {
"match_all": {}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
def search_data2(es):
query = {
"size": 0,
"aggs": {
"all_names": {
"terms": {
"field": "name.keyword",
"size": 10
},
"aggs": {
"total_grade": {
"sum": {
"field": "grade"
}
}
}
}
}
}
res = es.search(index='grade', body=query)
# print(res)
return res
if __name__ == '__main__':
start = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
size = 2000000
res = search_data(es, size)
all_source = []
for i in range(size):
source = res['hits']['hits'][i]['_source']
all_source.append(source)
# print(source)
# 统计查询出来的每个学生的所有课程的所有成绩的总成绩
start2 = time.time()
names1 = []
all_name_grade = {}
for data in all_source:
if data['name'] in names1:
all_name_grade[data['name']] += data['grade']
else:
names1.append(data['name'])
all_name_grade[data['name']] = data['grade']
print(all_name_grade)
end2 = time.time()
print("200万数据耗时:", end2 - start2)
end = time.time()
print('200万数据总耗时:', end - start)
# 聚合操作
start_aggs = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
res = search_data2(es)
# print(res)
aggs = res['aggregations']['all_names']['buckets']
# print(aggs)
dic = {}
for agg in aggs:
dic[agg['key']] = agg['total_grade']['value']
print('1000万数据:', dic)
end_aggs = time.time()
print('1000万数据总耗时:', end_aggs - start_aggs)运行结果:
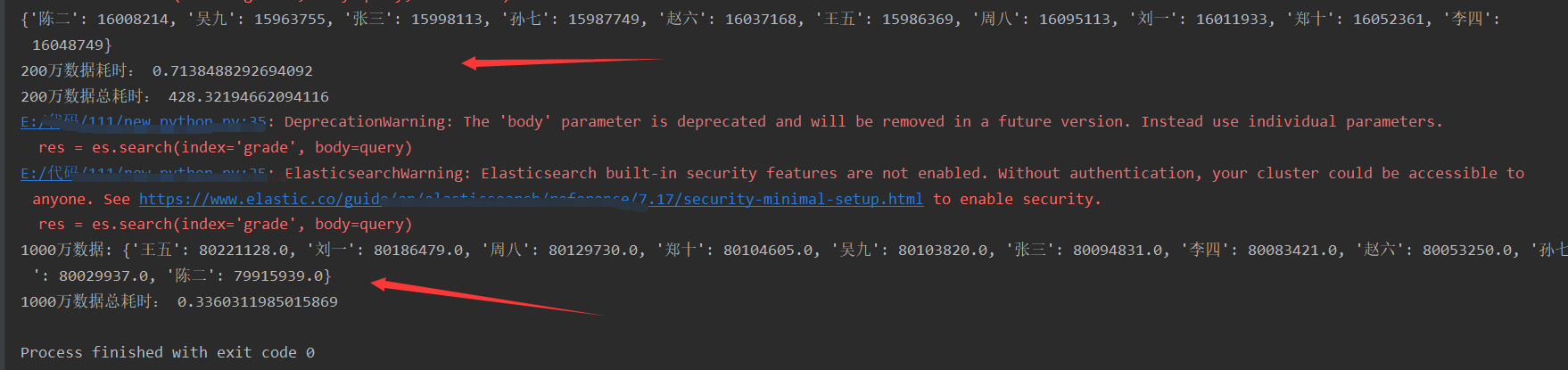
计算数据中每个同学的每科成绩之和。
示例代码7:
from elasticsearch import Elasticsearch
import time
def search_data(es, size=10):
query = {
"query": {
"match_all": {}
}
}
res = es.search(index='grade', body=query, size=size)
# print(res)
return res
def search_data2(es):
query = {
"size": 0,
"aggs": {
"all_names": {
"terms": {
"field": "name.keyword",
"size": 10
},
"aggs": {
"all_subjects": {
"terms": {
"field": "subject.keyword",
"size": 5
},
"aggs": {
"total_grade": {
"sum": {
"field": "grade"
}
}
}
}
}
}
}
}
res = es.search(index='grade', body=query)
# print(res)
return res
if __name__ == '__main__':
start = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
size = 2000000
res = search_data(es, size)
all_source = []
for i in range(size):
source = res['hits']['hits'][i]['_source']
all_source.append(source)
# print(source)
# 统计查询出来的每个学生的每门课程的所有成绩的总成绩
start3 = time.time()
names2 = []
subjects = []
all_name_all_subject_grade = {}
for data in all_source:
if data['name'] in names2:
if all_name_all_subject_grade[data['name']].get(data['subject']):
all_name_all_subject_grade[data['name']][data['subject']] += data['grade']
else:
all_name_all_subject_grade[data['name']][data['subject']] = data['grade']
else:
names2.append(data['name'])
all_name_all_subject_grade[data['name']] = {}
all_name_all_subject_grade[data['name']][data['subject']] = data['grade']
print('200万数据:', all_name_all_subject_grade)
end3 = time.time()
print("耗时:", end3 - start3)
end = time.time()
print('200万数据总耗时:', end - start)
# 聚合操作
start_aggs = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
res = search_data2(es)
# print(res)
aggs = res['aggregations']['all_names']['buckets']
# print(aggs)
dic = {}
for agg in aggs:
dic[agg['key']] = {}
for sub in agg['all_subjects']['buckets']:
dic[agg['key']][sub['key']] = sub['total_grade']['value']
print('1000万数据:', dic)
end_aggs = time.time()
print('1000万数据总耗时:', end_aggs - start_aggs)运行结果:
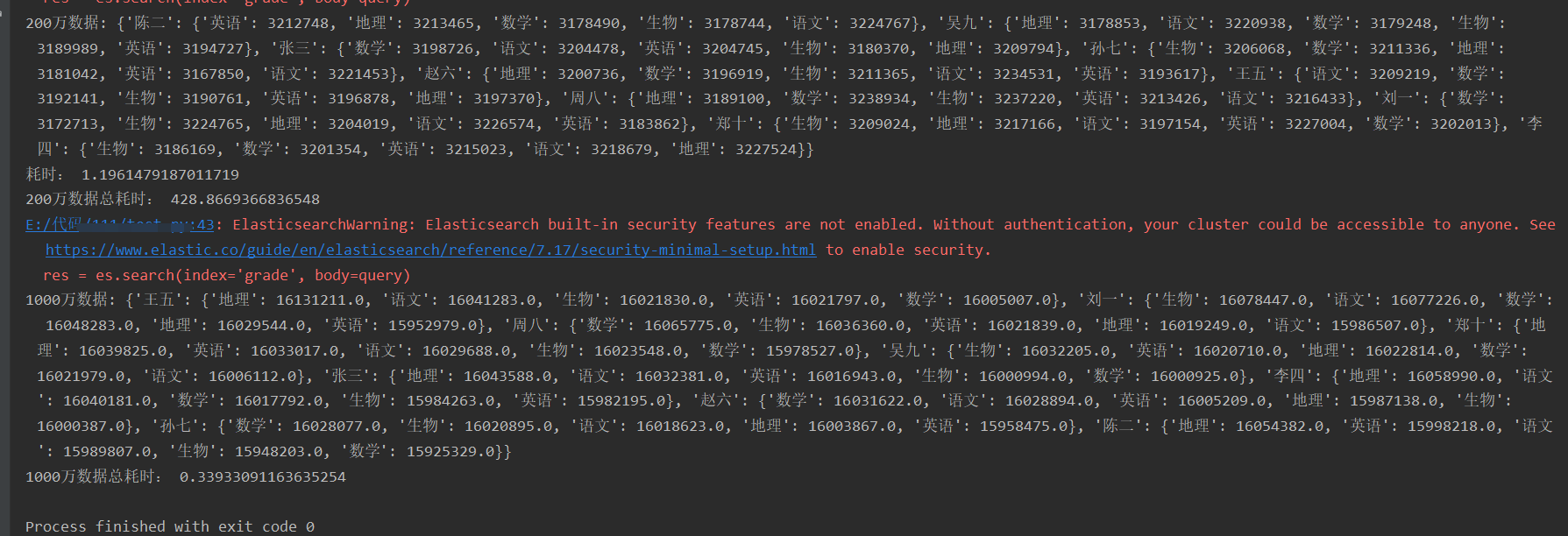
在上面查询计算示例代码中,当使用含有1000万数据的索引grade时,普通方法查询计算是比较耗时的,使用聚合查询能够大大节约大量时间。当面对9205万数据的索引grade2时,这时使用普通计算方法所消耗的时间太大了,在线上开发环境中是不可用的,所以必须使用聚合方法来计算。
示例代码8:
from elasticsearch import Elasticsearch
import time
def search_data(es):
query = {
"size": 0,
"aggs": {
"all_names": {
"terms": {
"field": "name.keyword",
"size": 10
},
"aggs": {
"all_subjects": {
"terms": {
"field": "subject.keyword",
"size": 5
},
"aggs": {
"total_grade": {
"sum": {
"field": "grade"
}
}
}
}
}
}
}
}
res = es.search(index='grade2', body=query)
# print(res)
return res
if __name__ == '__main__':
# 聚合操作
start_aggs = time.time()
es = Elasticsearch(hosts='http://127.0.0.1:9200')
res = search_data(es)
# print(res)
aggs = res['aggregations']['all_names']['buckets']
# print(aggs)
dic = {}
for agg in aggs:
dic[agg['key']] = {}
for sub in agg['all_subjects']['buckets']:
dic[agg['key']][sub['key']] = sub['total_grade']['value']
print('9205万数据:', dic)
end_aggs = time.time()
print('9205万数据总耗时:', end_aggs - start_aggs)运行结果:

注意:写查询语句时建议使用kibana去写,然后复制查询语句到代码中,kibana会提示查询语句。
到此这篇关于如何使用python生成大量数据写入es数据库并查询操作的文章就介绍到这了,更多相关python es 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
本站部分内容来源互联网,如果有图片或者内容侵犯您的权益请联系我们删除!