目录
- OneHotEncoder独热编码实例
- LabelEncoder标签编码实例
- OrdinalEncoder特征编码实例
OneHotEncoder独热编码实例
class sklearn.preprocessing.OneHotEncoder(*, categories='auto', drop=None, sparse=True, dtype=<class 'numpy.float64'>, handle_unknown='error')
- 目的:将分类要素编码为one-hot数字数组
- 输入:为整数或字符串之类的数组,表示分类(离散)特征所采用的值。
- 这将为每个类别创建一个二进制列,并返回一个稀疏矩阵或密集数组(取决于稀疏参数)默认情况下,编码器会根据每个功能中的唯一值得出类别(可改为手动)
- 适用于GBDT、XGBoost、Lgb模型中效果都不错 注意:在最新版本的sklearn中,所有的数据都应该是二维矩阵,所以当它只是单独一行或一列需要进行
reshape(1, -1)数据转换,否则会报错ValueError: Expected 2D array, got 1D array instead
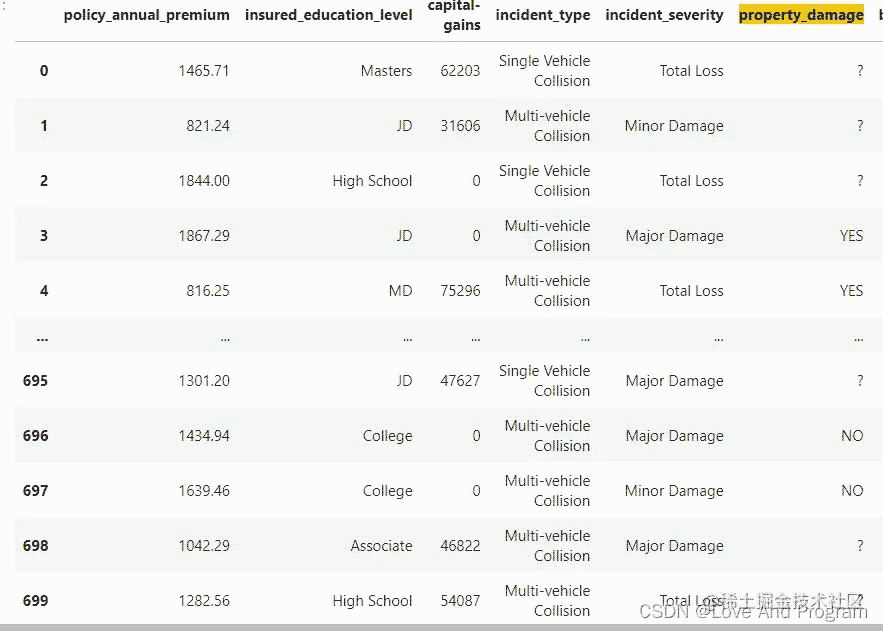
以下面数据为例(数据源):
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
train = pd.read_csv('./train.csv')
enc = OneHotEncoder(handle_unknown='ignore')
numerical_feature = ['policy_annual_premium','insured_education_level','capital-gains','incident_type','incident_severity',\
'property_damage','bodily_injuries','police_report_available','total_claim_amount','injury_claim','property_claim','vehicle_claim']
data = train[numerical_feature]
c = enc.fit_transform(data.values.reshape(1,-1))
c.toarray()#查看转化后的数据
输入数据由处理后的这种格式:

经过编码后得出编码后的数据(数据量过大用元组的形式展现),全部由二进制数0、1表示:
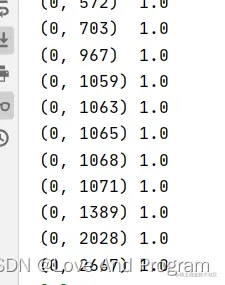
注意:在一对多的情况下y标签需要使用 sklearn.preprocessing.LabelBinarizer() 函数将多类标签转换为二进制标签
LabelEncoder标签编码实例
- 目的:对目标标签进行编码,其值介于0和n_classes-1之间
- 输入可以是数字标签,也可以是非数字标签,这里需要注意的是返回的类型是NumPy的array形式,上述
OneHotEncoder ()返回的是系数矩阵形式。
from sklearn.preprocessing import LabelEncoder
Enc=LabelEncoder()
def yuchuli(data):
numerical_feature = ['policy_annual_premium','insured_education_level','capital-gains','incident_type','incident_severity',\
'property_damage','bodily_injuries','police_report_available','total_claim_amount','injury_claim','property_claim','vehicle_claim','auto_year']
data=pd.DataFrame()
for fea in numerical_feature:
data.insert(len(data.columns),fea,Enc.fit_transform(train[fea].values))
return data
train_data = yuchuli(train)
经过编码后得出编码后的数据:
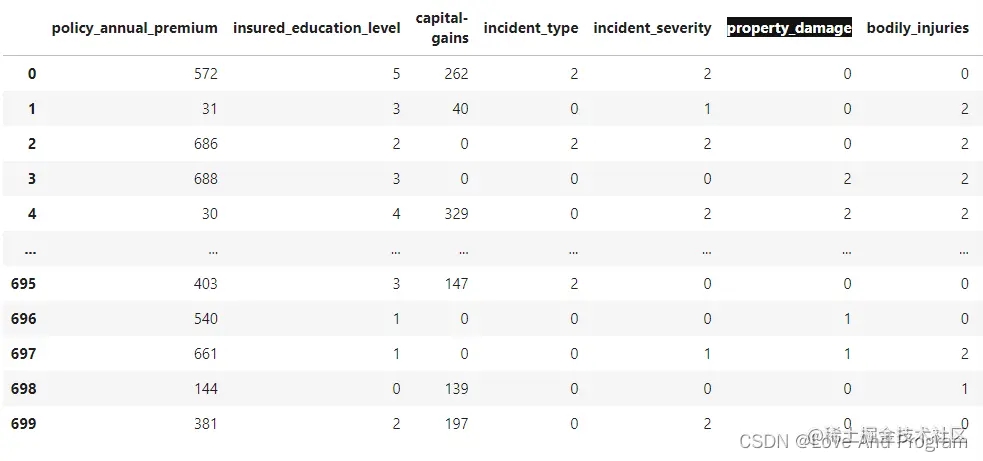
其中最清晰的就是标黑的property_damage一列,使用One-hot编码转换后变成?属于0,Yes属于2,No属于1。
LabelEncoder()只有一个class_属性,是查看每个类别的标签,在上述基础上尝试即最后一个特征所对应的属性标签,通俗来讲就是这里面需要被编码的个数就是这些数:

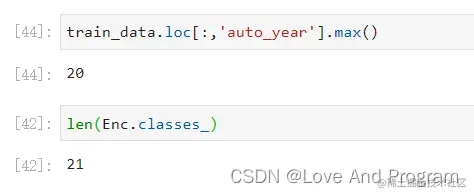
- 果然不出所料,因为这是循环,所以对应的最后一个是
auto_year,原数据如下图:

注意:开头提到的编码值介于 0 和 n_classes-1 之间于下图可以清晰理解,里面有n种不同的值,就分成 n-1 类,因为还包括 0
不过 LabelEncoder 标签编码我想对用的比较少,一般我都是使用 One-hot 独热编码去处理离散特征。
OrdinalEncoder特征编码实例
- 目的:将分类特征编码为整数数组。
- 输入:是一个类似数组的整数或字符串,表示分类(离散)特征所采用的值,特征会被转换为序数整数
from sklearn.preprocessing import OrdinalEncoder
import pandas as pd
import numpy as np
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
train.drop_duplicates()
Enc=LabelEncoder()
Enc=OneHotEncoder()
def yuchuli(data_train):
numerical_feature = ['incident_severity', 'insured_hobbies', 'vehicle_claim', 'auto_model', 'insured_education_level', 'insured_zip', 'insured_relationship', 'incident_date','auto_year']
data = pd.DataFrame()
for fea in numerical_feature:
data.insert(len(data.columns), fea, (Enc.fit_transform(train[fea].values.reshape(-1, 1))).tolist())
# return data
train_data = yuchuli(train)

但是我通过输出每一个特征结果的时候发现他和LabelEncoder()编码出的数据大差不离,特征编码则通过categories_查看编码特征

总而言之就是结果数据是一样的,但是类型上是不同的,我通过本文了解到它们本质的区别:
OrdinalEncoder用于形状为 2D 的数据(n_samples, n_features)LabelEncoder用于形状为 1D 的数据(n_samples,)
至于为什么,我们从上面两者的代码中就可以发现,OrdinalEncoder 编码出的数据要想fit_transform拟合,就得使用.reshape(-1, 1)转换成二维数据,这一块和OneHotEncoder编码相同,而LabelEncoder则直接放入即可拟合出数据来,这里也是使用过程中最容易出现的问题。
OrdinalEncoder编码还是有两点需要注意的,第一点,他可以接受np.nan缺失值,可根据需求选择是否处理缺失值;第二点,他有 这么一个参数->handle_unknown=error(默认) ,通过判断是否存在未知的特征来选择是否继续进行程序,当我们们选择handle_unknown=use_encoded_value时会将存在的未知特征打上unknown_value标签
#将缺失值全部处理为-1
Enc.set_params(encoded_missing_value=-1,handle_unknown=use_encoded_value).fit_transform()以上就是Python sklearn库三种常用编码格式实例的详细内容,更多关于Python sklearn库编码格式的资料请关注我们其它相关文章!