上周运维反馈线上程序出现了OOM,程序日志中的输出为
Exception in thread "http-nio-8080-exec-1027" java.lang.OutOfMemoryError: Java heap space
Exception in thread "http-nio-8080-exec-1031" java.lang.OutOfMemoryError: Java heap space看线程名称应该是tomcat的nio工作线程,线程在处理程序的时候因为无法在堆中分配更多内存出现了OOM,幸好JVM启动参数配置了-XX:+HeapDumpOnOutOfMemoryError,使用MAT打开拿到的hprof文件进行分析。
第一步就是打开Histogram看看占用内存最大的是什么对象:
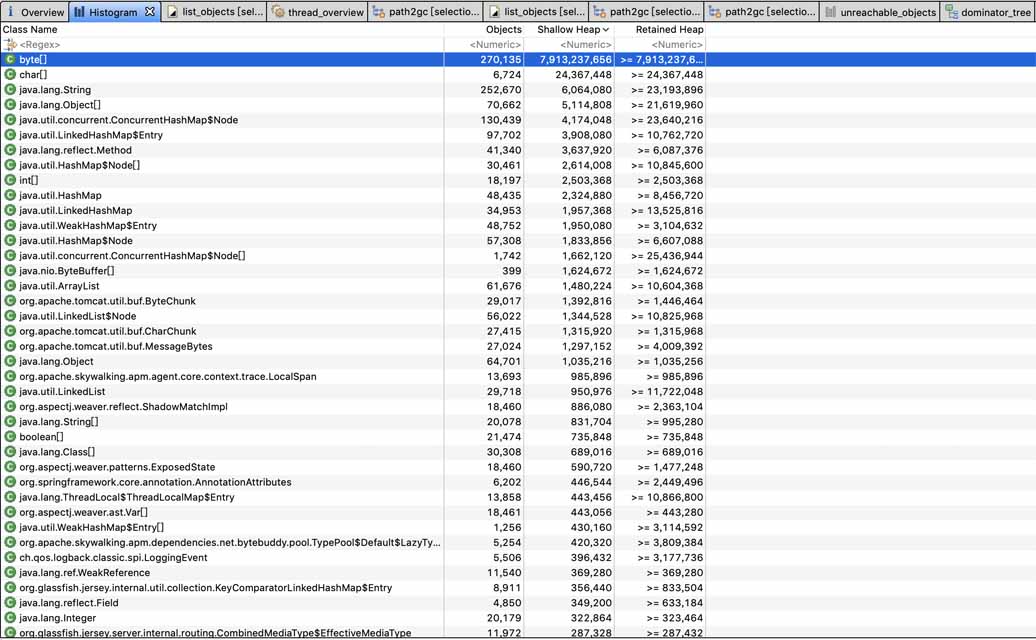
可以看到byte数组占用了接近JVM配置的最大堆的大小也就是8GB,显然这是OOM的原因。
第二步看一下究竟是哪些byte数组,数组是啥内容:
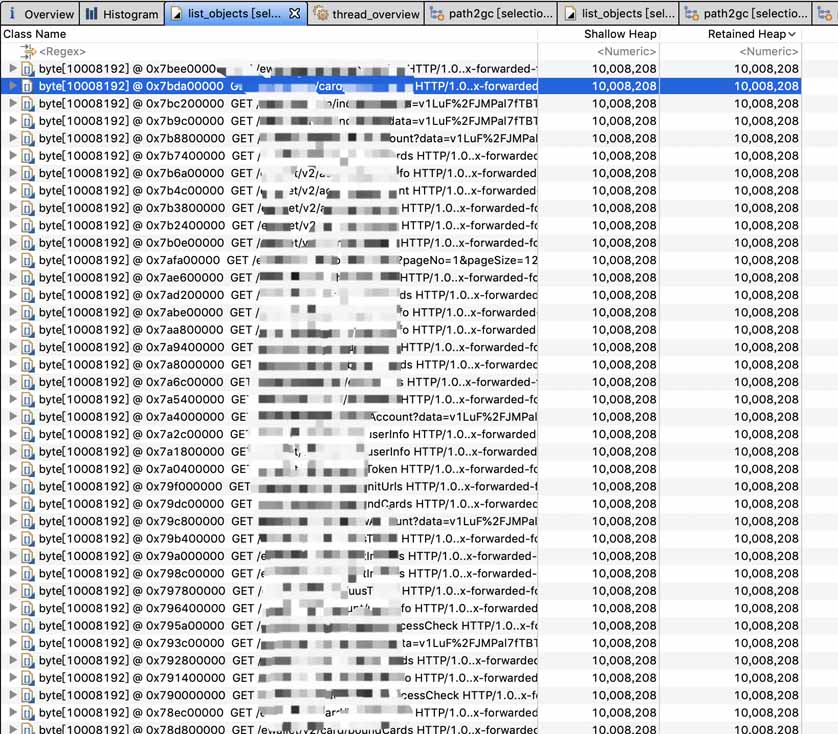
可以看到很明显这和HTTP请求相关,一个数组大概是10M的大小。
第三步通过查看GC根查看谁持有了数组的引用:

这符合之前的猜测,是tomcat的线程在处理过程中分配了10M的buffer在堆上。至此,马上可以想到一定是什么参数设置的不合理导致了这种情况,一般而言tomcat不可能为每一个请求分配如此大的buffer。
第四步就是检查代码里是否有tomcat或服务器相关配置,看到有这么一个配置:
max-http-header-size: 10000000至此,基本已经确定了八九不离十就是这个不合理的最大http请求头参数导致的问题。
到这里还有3个疑问:
- 即使一个请求分配10M内存,堆有8GB,难道当时有这么多并发吗?800个tomcat线程?
- 参数只是设置了最大请求头10M,为什么tomcat就会一次性分配这么大的buffer呢?
- 为什么会有如此多的tomcat线程?感觉程序没这么多并发。
先来看问题1,这个可以通过MAT在dump中继续寻找答案。
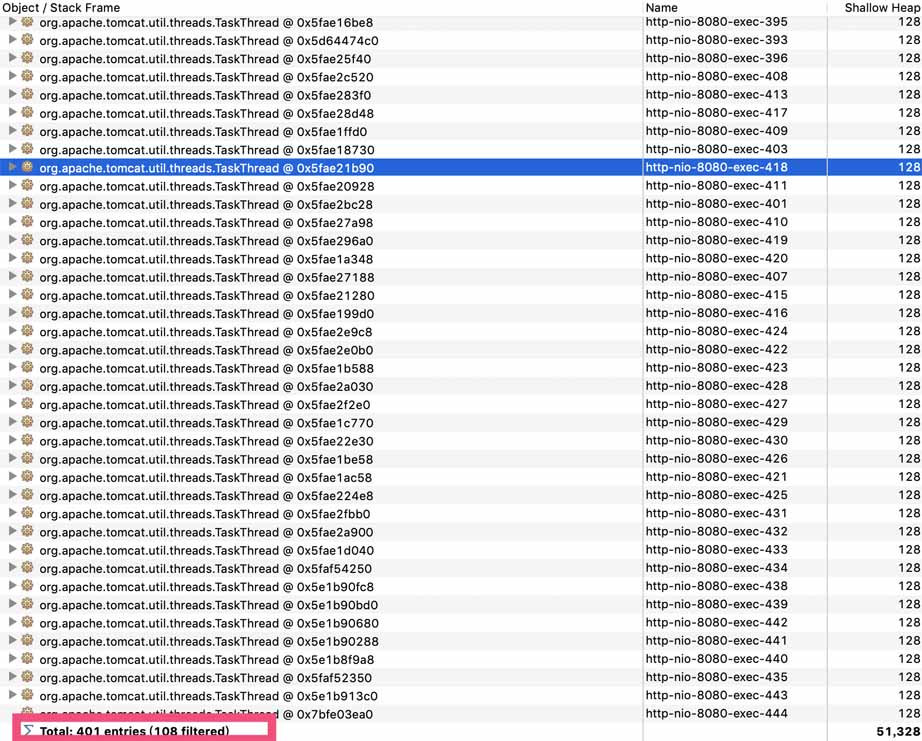
可以打开线程视图,搜索一下tomcat的工作线程,发现线程数量的确很多有401个,但是也只是800的一半:
再回到那些大数组的清单,按照堆分配大小排序,往下看:
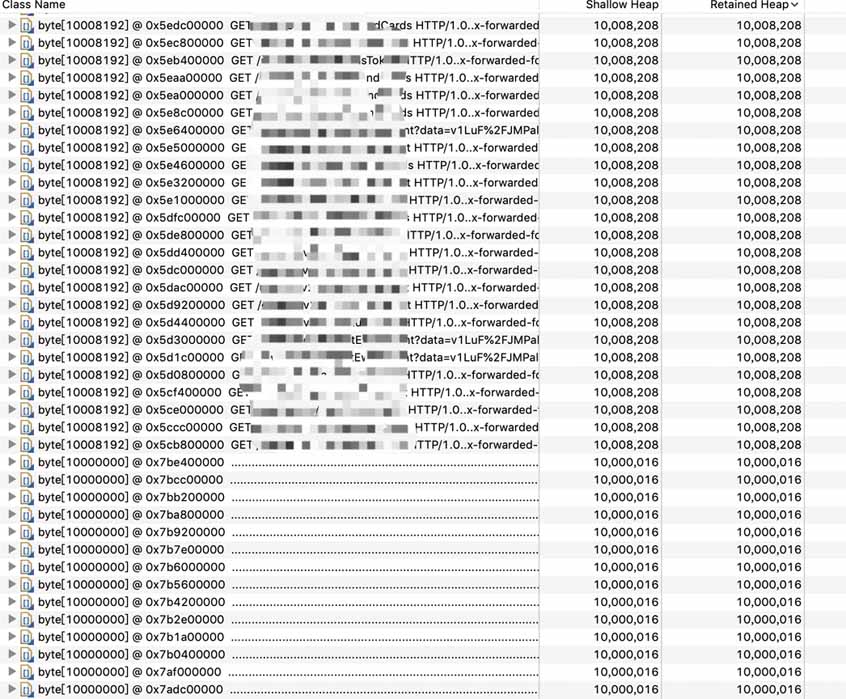
可以发现除了有10008192字节的数组还有10000000字节的数组,查看引用路径可以看到这个正好是10M的数组是output buffer,区别于之前看到的input buffer:
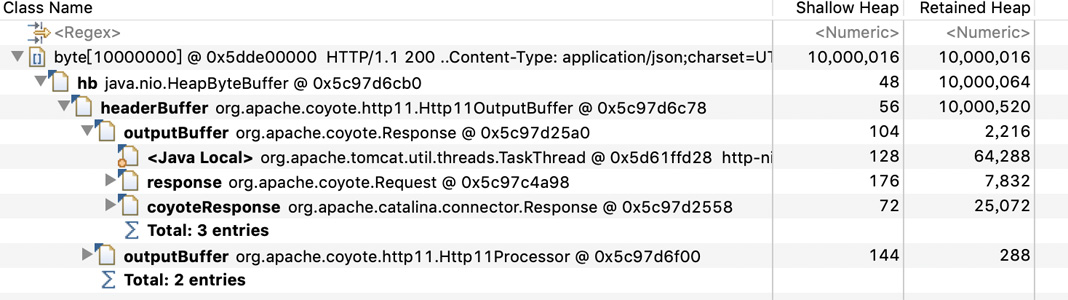
好吧,这就对了,一个线程分配了输入输出两个buffer,占用20M内存,一共401个线程,占用8GB,所以OOM了。
还引申出一个问题为啥有这么多工作线程,
再来看看问题2,这就需要来找一下源码了,首先max-http-header-size是springboot定义的参数,查看springboot代码可以看到这个参数对于tomcat设置的是MaxHttpHeaderSize:
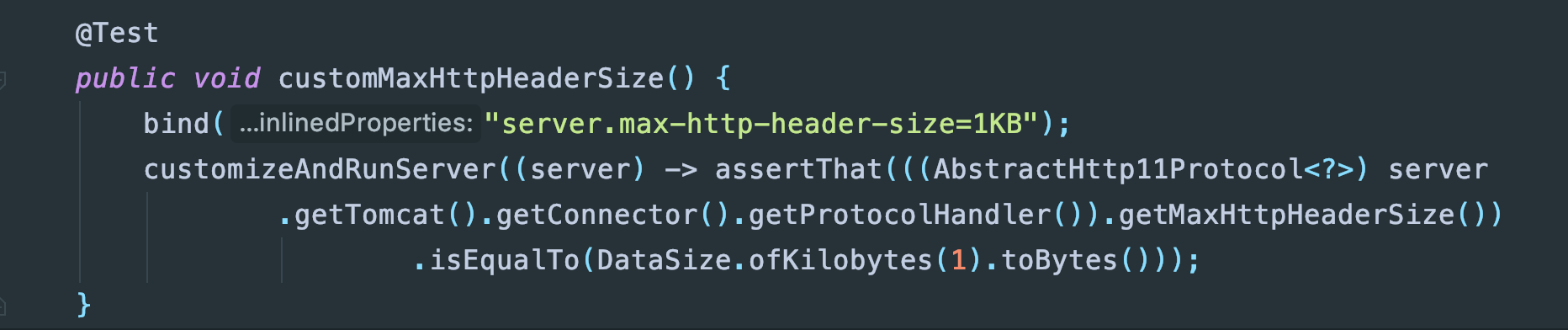
然后来看看tomcat源码:
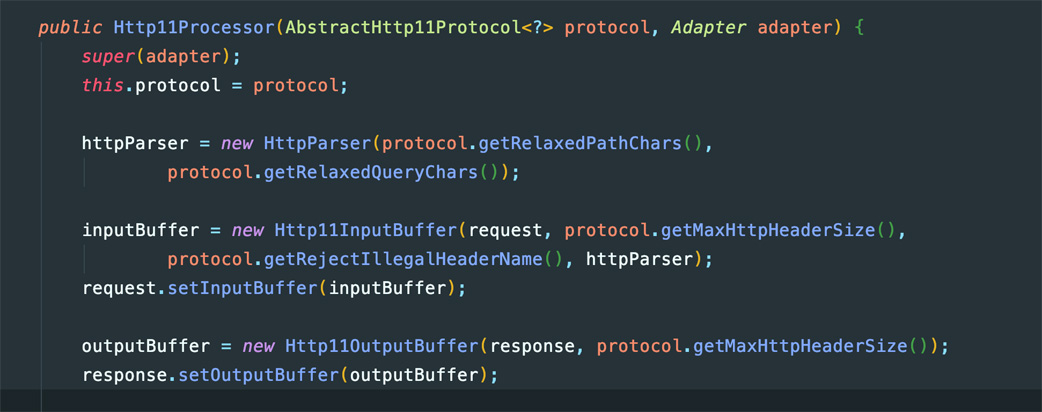
进一步看一下input buffer:
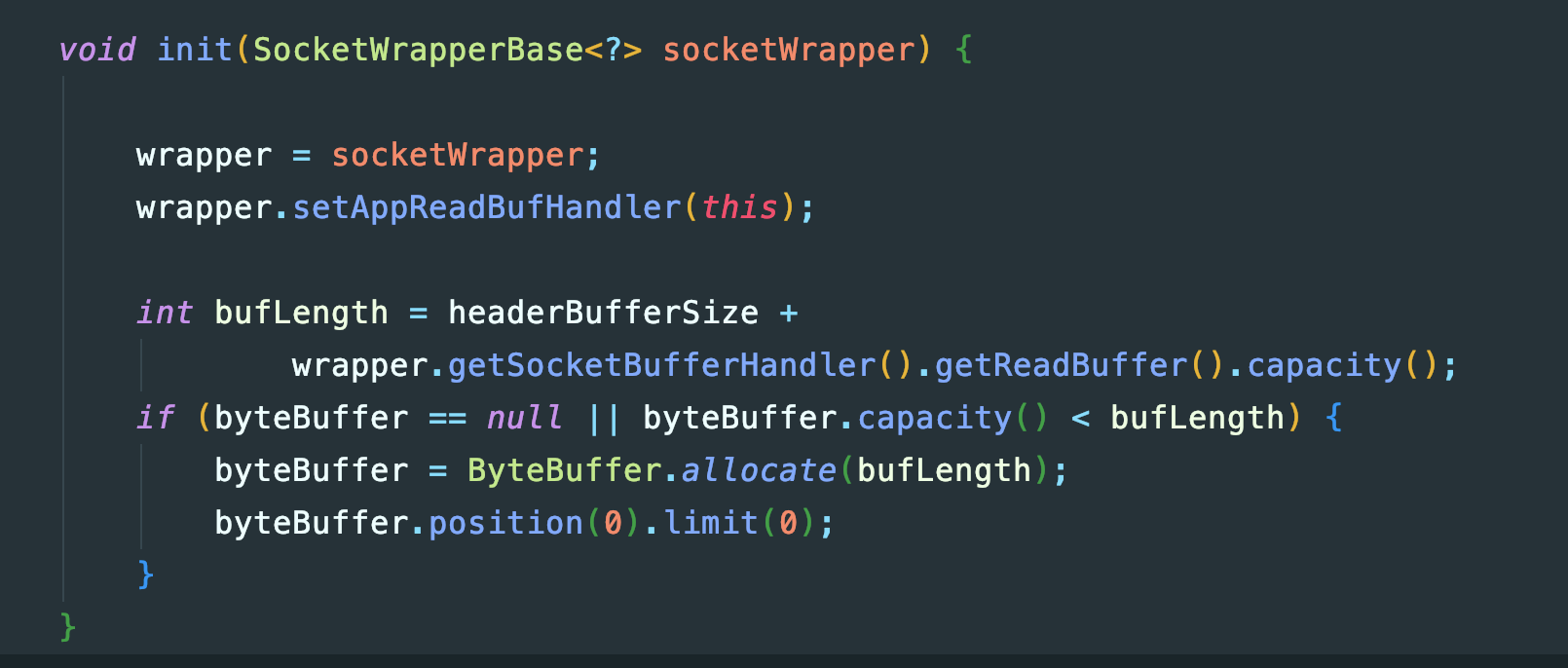
buffer大小是MaxHttpHeaderSize+ReadBuffer大小,这个默认是8192字节:
<attribute name="socket.appReadBufSize" required="false">
<p>(int)Each connection that is opened up in Tomcat get associated with
a read ByteBuffer. This attribute controls the size of this buffer. By
default this read buffer is sized at <code>8192</code> bytes. For lower
concurrency, you can increase this to buffer more data. For an extreme
amount of keep alive connections, decrease this number or increase your
heap size.</p>
</attribute>这也就是为什么之前看到大量的buffer是10008192字节的。至于为什么分配的buffer需要是MaxHttpHeaderSize+ReadBuffer。显然还有一批内容是空的10000000字节的buffer应该是output buffer,源码可以印证这点:
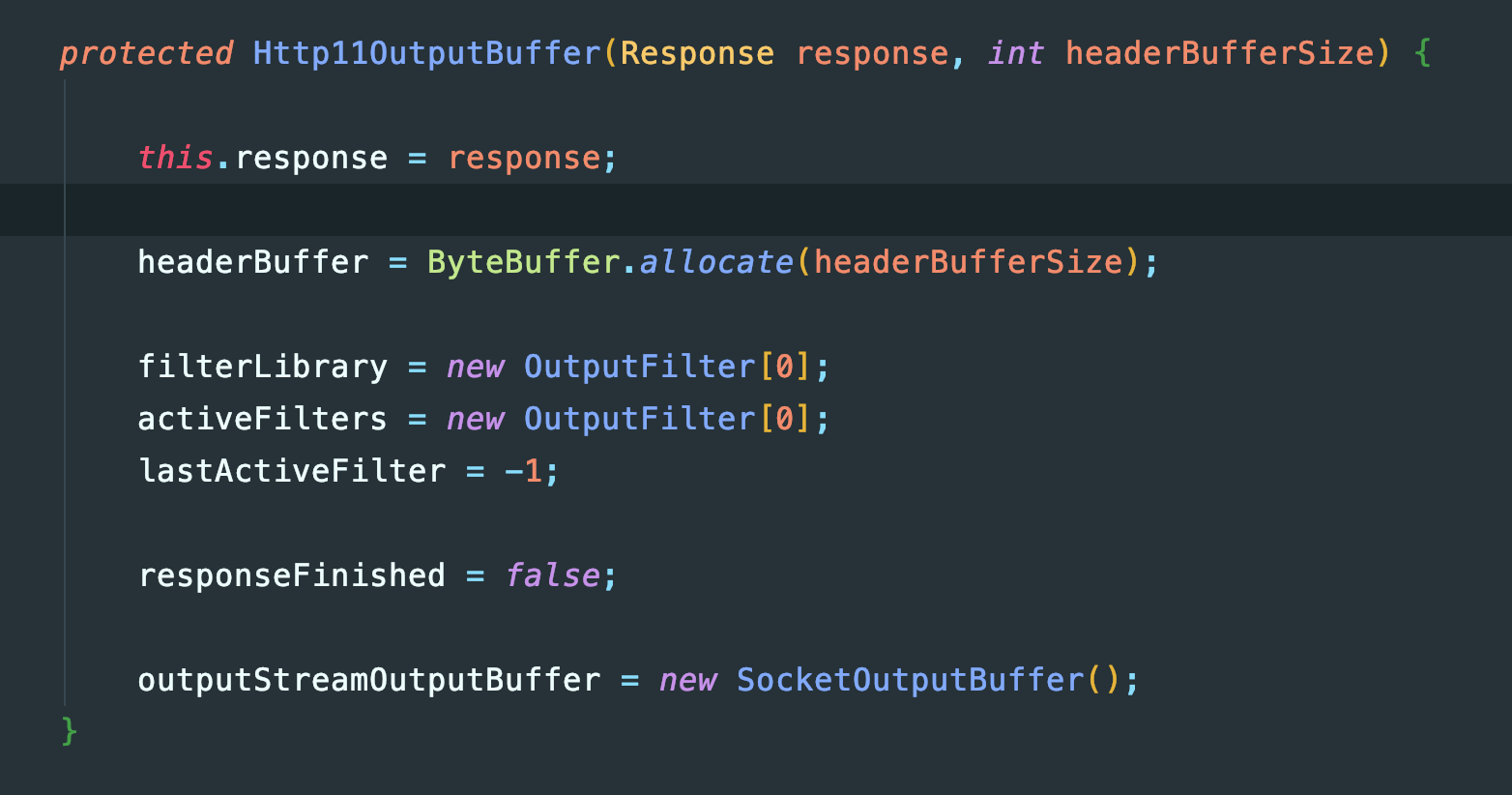
嗯这是一个header buffer,所以正好是10000000字节。
至于问题3,显然我们的应用程序是配置过最大线程的(查看配置后发现的确,我们配置为了2000,好吧有点大),否则也不会有401个工作线程(默认150),如果当时并发并不大的话就一种可能,请求很慢,虽然并发不大,但是因为请求执行的慢就需要更多线程,比如TPS是100,但是平均RT是4s的话,就是400线程了。这个问题的答案还是可以通过MAT去找,随便看几个线程可以发现很多线程都在等待一个外部服务的返回,这说明外部服务比较慢,去搜索当时的程序日志可以发现有很多"feign.RetryableException: Read timed out executing的日志"。。。。追杀下游去!慢点,我们的feign的timeout也需要再去设置一下,别被外部服务拖死了。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对得得之家的支持。