一、背景和现象
初创公司,架构lanmp,web前端和后端分开服务器,业务驱动主要是nginx和apache,nginx主要是处理静态文件和反向代理,前后端、搜索引擎、缓存、队列等附加的服务都是用docker容器部署。因为比较初级,上传文件和采集文件都是直接写在硬盘上,涉及到的目录共享,就在其中一台服务器存储并且nfs共享。我们暂且分为ECS1(apache1)、ECS2(apache2)、ECS3(nginx)。某天网站业务中断,但是没有报错。一直在等待响应,默认响应超时是一分钟,所以很基础高可用没有起到作用。中断10分钟左右,重启服务,提示“open too many files”,但是lsof统计没几个。因为初级处理不了,所以直接重启服务器,一段时间后一切恢复正常,可是第二天又来一次这种情况。
二、第一次出现后的排查思路
本来第一次发现这种问题的时候就要追查原因了,看了一下zabbix监控图像其中断了十分钟,包括网络、内存、CPU、硬盘、IO等监控数据。首先想到的是网络问题,结论是zabbix-servert获取不到了zabbix-agent采集的数据,估计就是网络不通了。
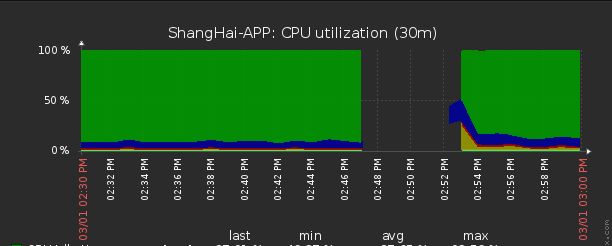
但是,这个结论站不住脚,因为我本身通过ssh登录服务器,并且命令输入无卡顿,不至于头文件都传不过来。后来一看阿里云的云监控,上面有数据,似乎也可以佐证网络这个说法,因为云监控是阿里云内部的监控,可以内网获取到监控数据。直到看CPU的使用率这项,发现有一段时间的CPU使用率100%。并且我重启的时候CPU恢复正常,不能说网络一定没问题,但系统肯定有问题。也可以解释因为CPU使用已经是100%,zabbix-agent和根本不能正常运行,所以没有监控数据。因为这个公司全部都是云服务器,没有使用IDC所以我们也没有安装smokeping来监控,接着我们就不把重心在网络上了。
目前掌握的信息就是:在毫无征兆的情况下,CPU暴涨到100%,重启之前一直保留,重启之后恢复原样。匆忙之中又看了一下系统各日志,因为太匆忙,没有总结,没有找到什么有价值的东西。现在有下面几种猜想:第一,程序的bug或者部署不当,触发之后耗尽资源。第二、docker容器的bug。第三、网络攻击。第四、病毒入侵。第五、阿里云方系统不稳定。
小总结了一下,现在问题还没有找出来。下次还有这个问题的可能,所以先尽量防范,但是又不能重启一刀切。所以在zabbix上面设置了自动化,当检测到ECS1获取不到数据的时候马上操作ECS3标记后端为ECS1的apache为down。保留异常现场。(请求停止的时候,CPU100%还在)
三、现场排查
1、相应的排查计划
(想到这些信息需要获取的,实际上没有严格按照这样的步骤)
1)用htop和top命令监控CPU、内存使用大的进程。先看看哪个进程消耗资源较多,用户态、内核态、内存、IO……同时sar -b查io的历史定时抽样。
2)统计tcp连接数,看看有没有DDOS攻击。netstat -anp |grep tcp |wc -l 。用iftop-i eth1看看通讯。同时用tail -n 1200 /var/log/messages查看内核日志。
3)用pstree查看打开进程,ps aux|wc-l看看有没有特别多的进程。虽然zabbix监控上说没有,但是我们要检查一下看看有没有异常的进程名字。
4)查看全部容器的资源使用docker stats $(docker ps -a -q),看看能不能从容器上排查。
5)有了“too many open files”的启发,计算打开文件数目lsof|wc -l,根据进程看看ll /proc/PID/fd文件描述符有没有可疑的打开文件、文件描述符。
6)关于用lsof打开文件数找到的线索,排序打开文件找出进程号 lsof -n|awk '{print $2}'|sort|uniq -c|sort -nr|more
7)关于用lsof打开文件数找到的线索,用lsof -p PID查看进程打开的句柄。直接查看打开的文件。
8)启动容器的时候又总是“open too many files"。那就是打开文件数的问题,因为CPU的使用率是CPU的使用时间和空闲时间比,有可能因为打开文件数阻塞而导致CPU都在等待。针对连接数的问题,大不了最后一步试试echo 6553500 > /proc/sys/fs/file-max 测试打开文件对CPU的影响。
9)玩意测出来了消耗CPU的进程,可以使用strace最终程序。用户态的函数调用跟踪用「ltrace」,所以这里我们应该用「strace」-p PID
10)从程序里面看到调用系统底层的函数可以跟踪。跟踪操作 strace -T -e * -p PID,主要看看代码调用的函数有没有问题。
2、现场排查
第二天同样时间,ECS果然暴涨了CPU。这是时候zabbix的工作如希望进行保留了一台故障的ECS1给我。
1)用htop看到资源使用最大是,搜索引擎下我写的一个判断脚本xunsearch.sh。脚本里面很简单,判断索引和搜索服务缺一个就全部重启。就当是我的容器有问题我直接关掉搜索引擎容器。httpd顶上,我又关掉apache容器。rabbitmq相关进程又顶上。这时候我没心情周旋了,肯定不也是这个原因。sar -b查看的历史io也没有异常。
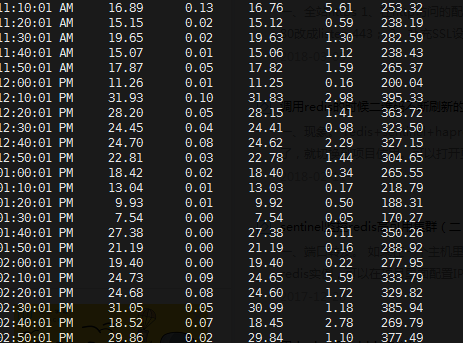
2)统计tcp连接,几百。先不用着重考虑攻击了。用tail -n 1200 /var/log/messages查看内核日志,是TCP TIME WAIT的错误。可以理解为CPU使用100%,程序无响应外面的tcp请求超时。这是结果,还是没有找到根本原因。
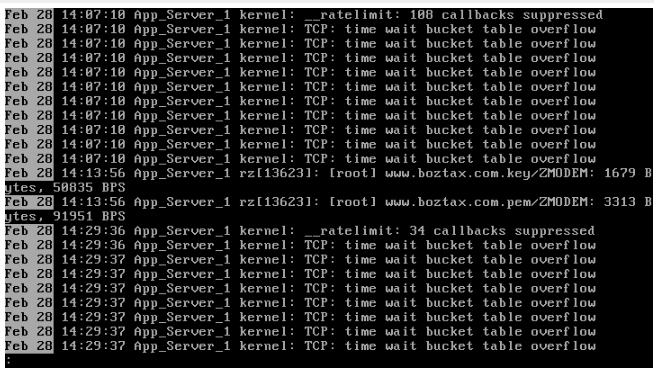
接着往下看系统内核日志,发现了和“open too many files”呼应的错误,“file-max limit 65535 reached”意思是,已到达了文件限制瓶颈。这里保持怀疑,继续收集其他信息。
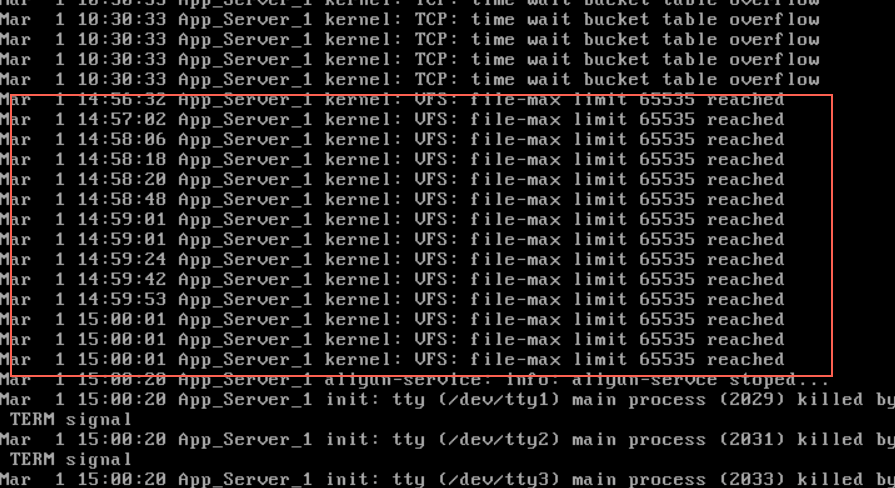
3)查看进程数量,数量几百。列出来也看到都是熟悉的进程,可以先排除异常进程。
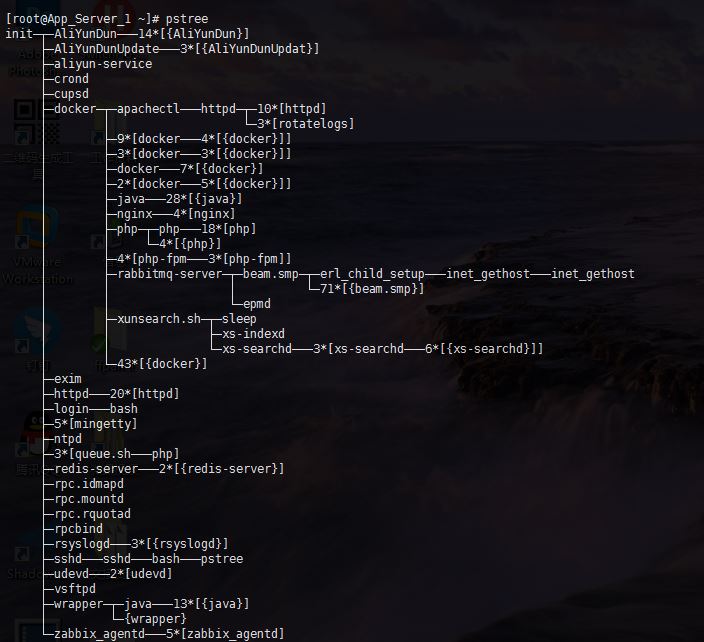
4)监控容器的资源使用,里面很不稳定,首先是xunsearch容器使用80%的CPU,关掉xunsearch,又变成了其他容器使用CPU最高。很大程度上可以排查容器的问题和执行程序的问题。
5)查看了最大连接数cat /proc/sys/fs/file-max是65535但是用lsof查到的连接数是10000多,完全没有达到连接数。
6)各项参数都正常,现在聚焦在打开的文件数这个问题上面。也可以用另外同一种方式查看一下内核统计文件 /proc/sys/fs/file-nr,比较一下差异,看看能不能找出问题。cat了一下,打开文件数是66080,果然超了!内核日志就以这个为标准。

但是看lsof怎么统计不出来,ll /proc/PID/fd也没几个。这个问题放在后面,先按照步骤echo 6553500 > /proc/sys/fs/file-max给连接数提高到100倍,CPU果然降了下来。原因确认了,但是必须找到根源,为什么忽然有这么大的打开文件数。关掉全部docker容器和docker引擎,打开文件数是少了一点,但是仍然在65535差不多。我就先排除一下业务的影响,把ECS3的nginx直接指向视频ECS2的apache,就等同于在ECS2上实现了ECS1的场景。查看一下ECS2的句柄数,才4000多,排除了业务相关应用对服务器的影响。那就能下个小结论,ECS1被神秘程序打开了6万多句柄数,打开业务就多了2000多的句柄数,然后就崩溃了。不过这个现象有点奇怪,ECS2和ECS1在一样的机房一样的配置一样的网络环境,一样的操作系统,一样的服务,一样的容器,为什么一个有问题,一个没问题呢?不同的只是有一台是共享nfs。难道是静态文件共享了,其他人读了,也算是本服务器打开的?
7)现在程序找不到,没法继续lsof -p了。排查之前的猜想。带着排查得到对的结论往下想。
程序的bug和部署不当,那是不可能的,因为主要问题来自于打开句柄数,当部署到ECS2那里,一切正常。docker容器的bug,那也不可能的,每个都是我亲自写脚本,亲自编译,亲自构建的,关键是我关掉了docker容器和引擎都没有很大改善。网络攻击也排除,因为网络连接数没几个,流量也不变。那就只剩下病毒入侵也不是,没有异常进程。考虑到ECS的稳定性问题了。这方面就协助阿里云工程师去排查。
8)阿里云工程师用的排查手段和我差不多,最终也是没能看到什么。也只是给了我一些治标不治本的建议。后来上升到专家排查,专家直接在阿里云后端抓取了coredump文件分析打开的文件是图片,程序是nfsd。

好像印证了我刚才后面的猜想,应该就是ECS1使用了nfs共享其他服务器打开了然后算在ECS1头上。那问题又来了,我们的业务已经到达了可以影响服务器的程度吗?
9)既然问题解决到这一步,先不管程序有没有关闭打开的文件和nfs的配置。我们架构上面的图片应该是归nginx读取,难道是linux的内存机制让它缓存了。带着缓存的问题,首先去ECS3上释放内存echo 3 > /proc/sys/vm/drop_caches,释放之后,发现没什么改善,有点失落。总是觉得还有一台后端是PHP主导,但是逻辑上是写入,没有打开文件之说。后来从程序员中了解到,PHP也有打开图片。我猛然去ECS2释放一下内存,果然,句柄数降下来。(这里大家一定有个疑问,为什么我直接想到内存缓存而不是目前打开的文件呢。其一,这是生产环境,web前端只有一个,不能乱来停服务。其二,第一次遇到问题的时候,重启之后没有问题,过了一天之后积累到一定的程度才爆发,这里已经引导了我的思路是积累的问题,那就是缓存不断积累了)
10)因为ECS2的调用ECS1的nfs共享文件,所以lsof也有读不到那么多句柄数的理由。如果说是nfs的服务本身就有缓存,导致问题的话,我查看了配置文件,还是默认值允许缓存,30S过期,根本不会因为nfs的缓存造成打开文件过多。如果我们的后端程序打开之后没好好处理的话,那倒有可能。然后尝试排除:我改了ECS3的配置,使程序只读ECS1后端,从ECS1上面却看不到有什么异常表现,说明PHP程序已经好好处理了打开的文件。也不是docker挂载了nfs的共享的问题,因为nginx也有挂载。排查到这里也很大程度上解决问题,而且缓存了nfs的全部共享文件,句柄并没有增加,也算合理,所以就增加了打开文件数的限制。
11)现在排查的结果是跟后端和nfs共享有关。就是说,后端挂载了nfs的网络共享,被程序读取。而程序释放之后,在正常背景的硬盘文件是没有缓存的。但是在nfs挂载的环境下,缓存并没有得到释放。
12)总结:很多问题的排查和我们的猜想结果一样,但是有些例外的情况。比如这次我想到的原因都一一排除,但是问题也是在一步步排查中,逐步被发现的。
以上就是阿里云ECS的CPU100%排查分析的详细内容,更多关于阿里云ECS的CPU100%排查的资料请关注编程学习网其它相关文章!