1.摘要
Apache Hudi 的Payload是一种可扩展的数据处理机制,通过不同的Payload我们可以实现复杂场景的定制化数据写入方式,大大增加了数据处理的灵活性。Hudi Payload在写入和读取Hudi表时对数据进行去重、过滤、合并等操作的工具类,通过使用参数 "hoodie.datasource.write.payload.class"指定我们需要使用的Payload class。本文我们会深入探讨Hudi Payload的机制和不同Payload的区别及使用场景。
2. 为何需要Payload
在数据写入的时候,现有整行插入、整行覆盖的方式无法满足所有场景要求,写入的数据也会有一些定制化处理需求,因此需要有更加灵活的写入方式以及对写入数据进行一定的处理,Hudi提供的playload方式可以很好的解决该问题,例如可以解决写入时数据去重问题,针对部分字段进行更新等等。
3. Payload的作用机制
写入Hudi表时需要指定一个参数hoodie.datasource.write.precombine.field,这个字段也称为Precombine Key,Hudi Payload就是根据这个指定的字段来处理数据,它将每条数据都构建成一个Payload,因此数据间的比较就变成了Payload之间的比较。只需要根据业务需求实现Payload的比较方法,即可实现对数据的处理。
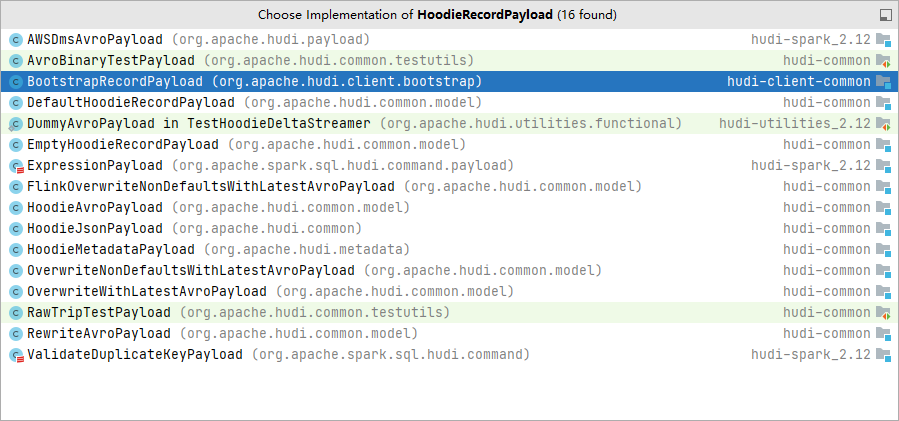
Hudi所有Payload都实现HoodieRecordPayload接口,下面列出了所有实现该接口的预置Payload类。
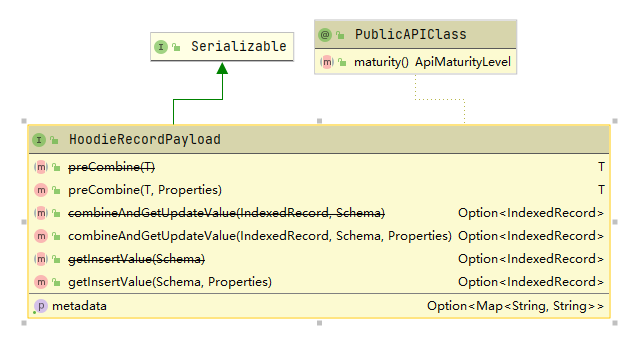
下图列举了HoodieRecordPayload接口需要实现的方法,这里有两个重要的方法preCombine和combineAndGetUpdateValue,下面我们对这两个方法进行分析。
3.1 preCombine分析
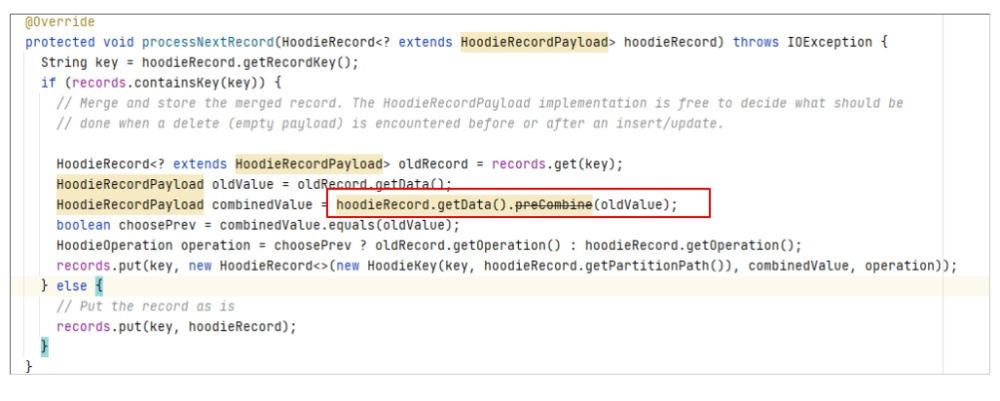
从下图可以看出,该方法比较当前数据和oldValue,然后返回一条记录。
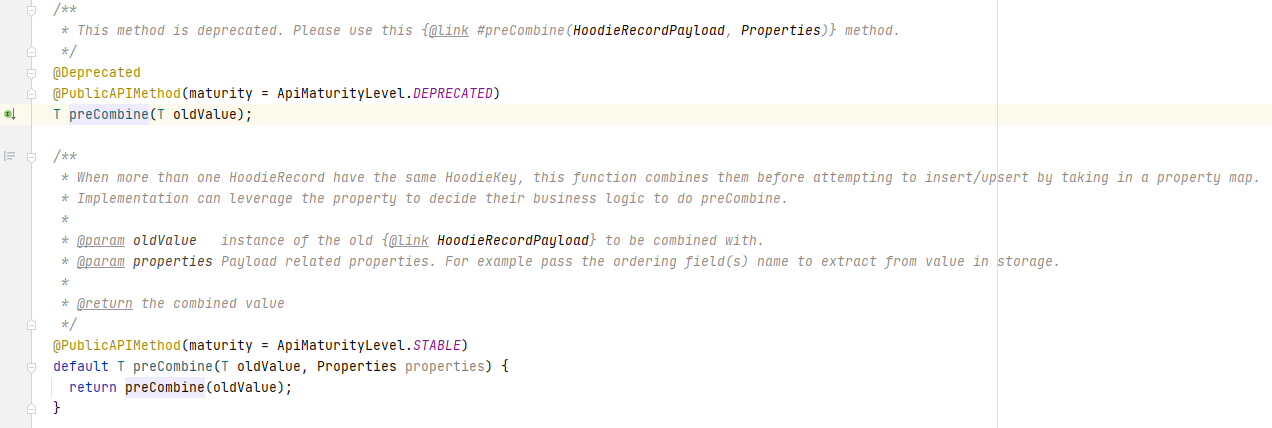
从preCombine方法的注释描述也可以知道首先它在多条相同主键的数据同时写入Hudi时,用来进行数据去重。
调用位置
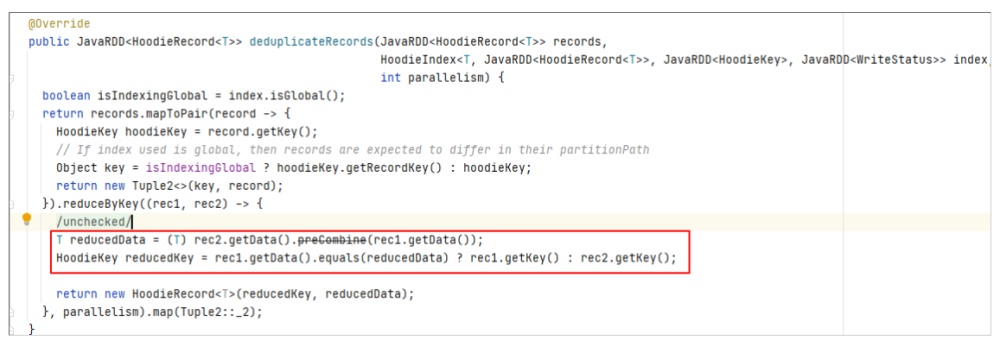
其实该方法还有另一个调用的地方,即在MOR表读取时会对Log file中的相同主键的数据进行处理。
如果同一条数据多次修改并写入了MOR表的Log文件,在读取时也会进行preCombine。
3.2 combineAndGetUpdateValue分析
该方法将currentValue(即现有parquet文件中的数据)与新数据进行对比,判断是否需要持久化新数据。
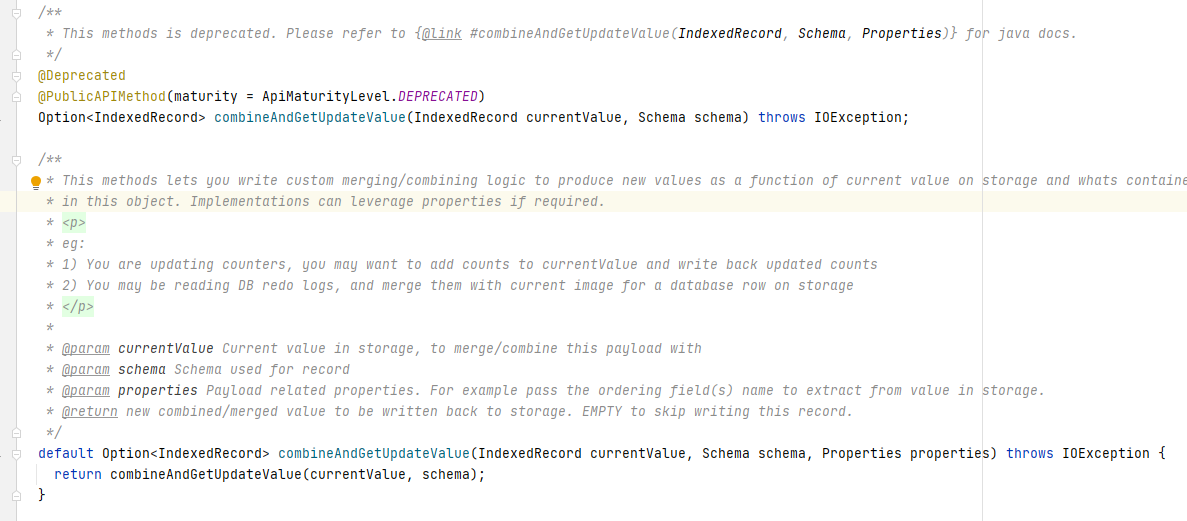
由于COW表和MOR表的读写原理差异,因此combineAndGetUpdateValue的调用在COW和MOR中也有所不同:
在COW写入时会将新写入的数据与Hudi表中存的currentValue进行比较,返回需要持久化的数据
在MOR读取时会将经过preCombine处理的Log中的数据与Parquet文件中的数据进行比较,返回需要持久化的数据
4.常用Payload处理逻辑的对比
了解了Payload的内核原理,下面我们对比分析下集中常用的Payload实现的方式。
4.1 OverwriteWithLatestAvroPayload
OverwriteWithLatestAvroPayload 的相关方法实现如下

可以看出使用OverwriteWithLatestAvroPayload 会根据orderingVal进行选择(这里的orderingVal即precombine key的值),而combineAndGetUpdateValue永远返回新数据。
4.2 OverwriteNonDefaultsWithLatestAvroPayload
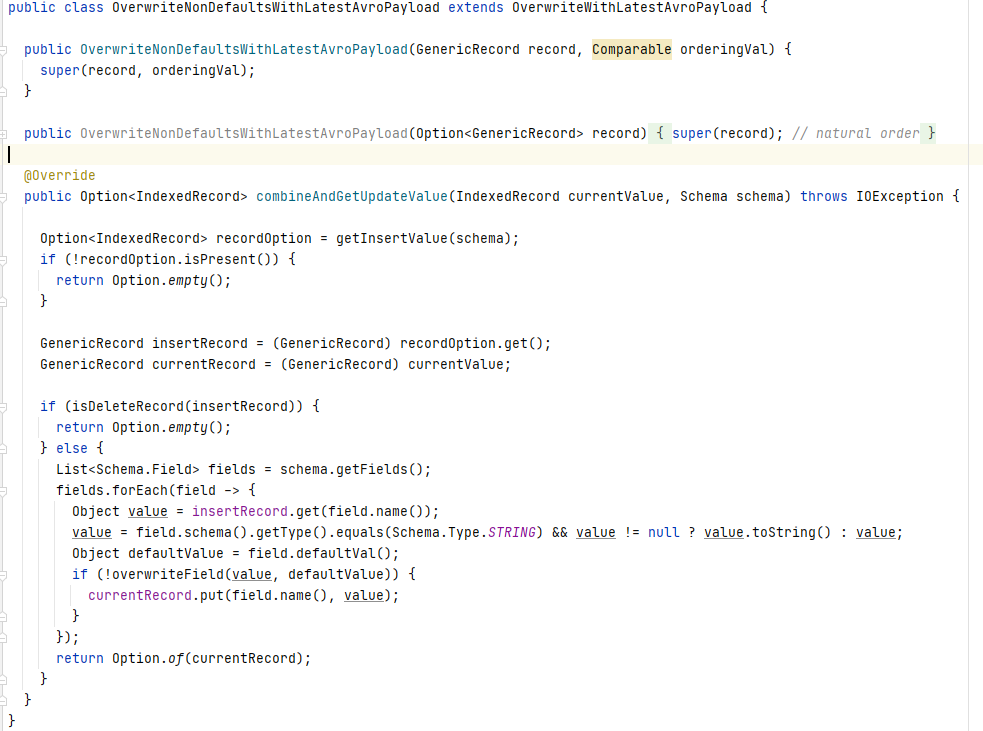
OverwriteNonDefaultsWithLatestAvroPayload继承OverwriteWithLatestAvroPayload,preCombine方法相同,重写了combineAndGetUpdateValue方法,新数据会按字段跟schema中的default value进行比较,如果default value非null且与新数据中的值不同时,则在新数据中更新该字段。由于通常schema定义的default value都是null,在此场景下可以实现更新非null字段的功能,即如果一条数据有五个字段,使用此Payload更新三个字段时不会影响另外两个字段原来的值。
4.3 DefaultHoodieRecordPayload
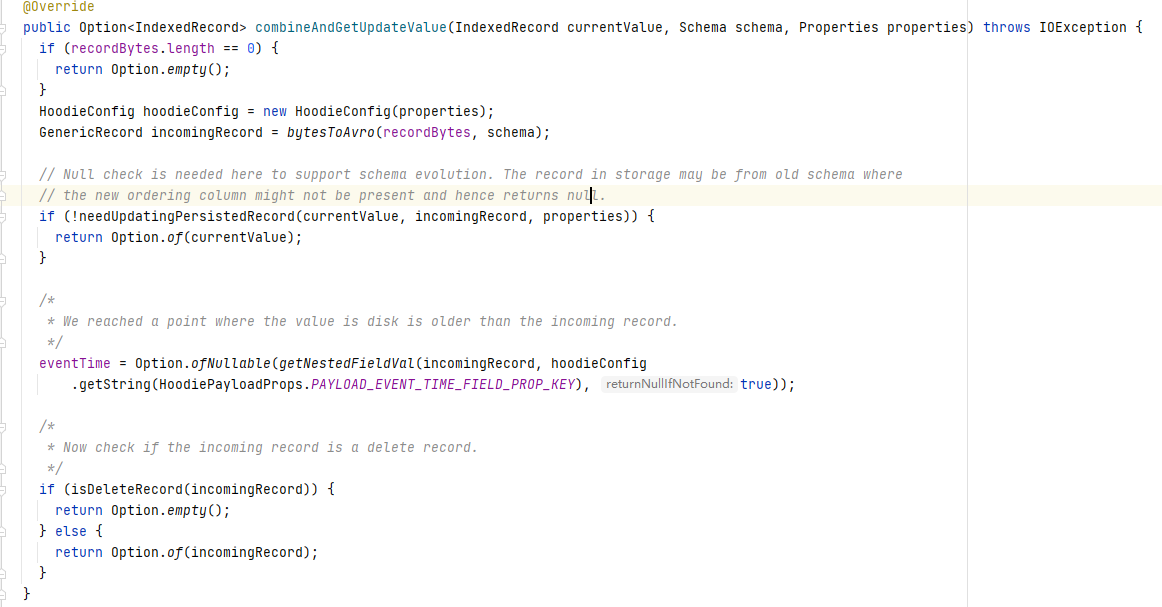
DefaultHoodieRecordPayload同样继承OverwriteWithLatestAvroPayload重写了combineAndGetUpdateValue方法,通过下面代码可以看出该Payload使用precombine key对现有数据和新数据进行比较,判断是否要更新该条数据。
下面我们以COW表为例展示不同Payload读写结果测试
5. 测试
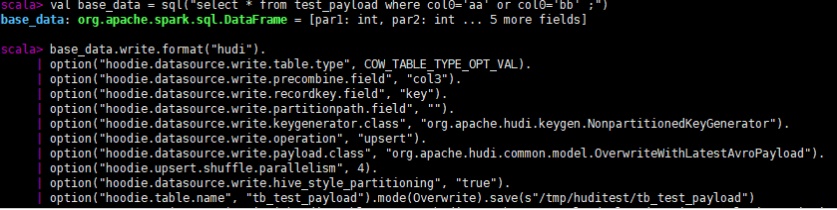
我们使用如下几条源数据,以key为主键,col3为preCombine key写Hudi表。

首先我们一次写入col0是'aa'、'bb'的两条数据,由于他们的主键相同,所以在precombine时会根据col3比较去重,最终写入Hudi表的只有一条数据。(注意如果写入方式是insert或bulk_insert则不会去重)
查询结果

下面我们使用col0是'cc'的数据进行更新,这是由于三种Payload的处理逻辑不同,最终写入的数据结果也不同。
OverwriteWithLatestAvroPayload完全用新数据覆盖了旧数据。

OverwriteNonDefaultsWithLatestAvroPayload由于更新数据中col1 col2为null,因此该字段未被更新。

DefaultHoodieRecordPayload由于cc的col3小于bb的,因此该数据未被更新。

6. 总结
通过上面分析我们清楚了Hudi常用的几种Payload机制,总结对比如下
| Payload | 更新逻辑与适用场景 |
|---|---|
| OverwriteWithLatestAvroPayload | 永远用新数据更新老数据全部字段,适合每次更新数据都是完整的 |
| OverwriteNonDefaultsWithLatestAvroPayload | 将新数据中的非空字段更新到老数据中,适合每次更新数据只有部分字段 |
| DefaultHoodieRecordPayload | 根据precombine key比较是否要更新数据,适合实时入湖且入湖顺序乱序 |
虽然Hudi提供了多个预置Payload,但是仍不能满足一些特殊场景的数据处理工作:例如用户在使用Kafka-Hudi实时入湖,但是用户的一条数据的修改不在一条Kafka消息中,而是多条相同主键的数据消息到,第一条里面有col0,col1的数据,第二条有col2,col3的数据,第三条有col4的数据,这时使用Hudi自带的Payload就无法完成将这三条数据合并之后写入Hudi表的工作,要实现这个逻辑就要通过自定义Payload,重写Payload中的preCombine和combineAndGetUpdateValue方法来实现相应的业务逻辑,并在写入时通过hoodie.datasource.write.payload.class指定我们自定义的Payload实现
以上就是Apache Hudi灵活的Payload机制硬核解析的详细内容,更多关于Apache Hudi Payload机制解析的资料请关注编程学习网其它相关文章!