Introduction basic of kubernetes
我们要学习 Kubernetes,就有首先了解 Kubernetes 的技术范围、基础理论知识库等,要学习 Kubernetes,肯定要有入门过程,在这个过程中,学习要从易到难,先从基础学习。
那么 Kubernetes 的入门基础内容(表示学习一门技术前先了解这门技术)包括哪些?
根据 Linux 开源基金会的认证考试,可以确认要了解 Kubernetes ,需要达成以下学习目标:
- Discuss Kubernetes.
- Learn the basic Kubernetes terminology.
- Discuss the configuration tools.
- Learn what community resources are available.
接下来笔者将一一介绍 Kubernetes 的一些概念(Discuss)、技术术语(Terminology)、相关配置工具以及社区开源资源(Community resources)。
本系列教程将会混杂一些英文,因为研究和使用 Kubernetes 的过程中,会接触到大量英文,并且 Kubernetes 的国际认证考试,都是英文考试,多接触一些英文单词,慢慢积累吧。。。
本系列教程主要参考 Linux 开源基金会的课程内容及 Kubernetes 文档,课程内容按照 Attribution 3.0 Unported (CC BY 3.0) 协议,在写作时参考、复制网站内容、共享知识库等。关于 CC BY 3.0 协议,其说明如下:
- 共享—以任何媒介或格式复制和重新分发材料
- 适应-重新混合,变换并在材料上构建
- 出于任何目的,甚至出于商业目的。
Linux 开源基金会认证考试与课程学习网址:
https://training.linuxfoundation.org/#
使用条款:
https://www.linuxfoundation.org/terms/
学习 Kubernetes 后,可以进一步考取以下认证证书:
Kubernetes 管理员认证 (CKA)、Kubernetes 应用程序开发者认证 (CKAD)、Kubernetes安全专家认证 (CKS)。
What Is Kubernetes?
我们先思考一下,运行一个 Docker 容器,只需要使用 docker run ... 命令即可,这是相当简单(relatibely simple)的方法。
但是,要实现以下场景,则是困难的:
- 跨多台主机的容器相互连接(connecting containers across multiple hosts)
- 拓展容器(scaling containers)
- 在不停机的情况下配置应用(deploying applications without downtime)
- 在多个方面进行服务发现(service discovery among several aspects)
在 2008年,LXC(Linux containers) 发布第一个版本,这是最初的容器版本;2013 年,Docker 推出了第一个版本;而 Google 则在 2014 年推出了 LMCTFY。
为了解决大集群(Cluster)中容器部署、伸缩和管理的各种问题,出现了 Kubernetes、Docker Swarm 等软件,称为 容器编排引擎。
Kubernetes 是什么?
"an open-source system for automating deployment, scaling, and management of containerized applications".
“一个自动化部署、可拓展和管理容器应用的开源系统”
Google 的基础设施在虚拟机(Virtual machines)技术普及之前就已经达到了很大的规模,高效地(Efficiency)使用集群和管理分布式应用成为 Google 挑战的核心。而容器技术提供了一种高效打包集群的解决方案。
多年来,Google 一直使用 Borg 来管理集群中的容器,积累了大量的集群管理经验和运维软件开发能力,Google 参考 Borg ,开发出了 Kubernetes,即 Borg 是 Kubernetes 的前身。(但是 Google 目前还是主要使用 Borg)。
Kubernetes 从一开始就通过一组基元(primitives)、强大的和可拓展的 API 应对这些挑战,添加新对象和控制器地能力可以很容易地地址各种各样的产品需求(production needs)。
因为 Kubernetes 这个单词不好发音,而 k 和 s 之间有 8 个单词,因此一般大家都读 k 8 s。
Kubernetes 是使用 Go 语言编写的。
当然,除了 Kubernetes ,还有 Docker Swarm、Apache Mesos、Nomad、Rancher 等软件可以监控容器状态、动态伸缩等。
Components of Kubernetes
Kubernetes 的组件分为两种,分别是 Control Plane Components(控制平面组件)、Node Components(节点组件)。
Control Plane Components 用于对集群做出全局决策;
Node Components 在节点中运行,为 Pod 提供 Kubernetes 环境。
Docker 和 Kubernetes 并不是想上就上的,这可能需要改变开发模式和系统管理方法(system administration approach)。在传统环境中,会在一台专用服务器(dedicated server)部署(Deploy)单一的应用(a monolithic application),当业务发展后,需要更大的流量带宽、CPU和内存,这时可能对程序进行大量的定制(提高性能、缓存优化等),同时也需要更换更大的硬件(hardware)。
而在使用 Kubernetes 的解决方案中,是使用更多的小型服务器或者使用微服务的方式,去替代单一的、大型的一台服务器模式。
例如,为了保证服务可靠性,当一台主机的服务进程挂掉后,会启用另一台服务器去替代服务;如果单台服务器配置非常高,那么成本必定也会很高,这种方案的实现成本会比较高。而使用 Kubernetes 的方案中,当一台服务器或进程挂掉后,启动另一台服务器,可能只需要不到 1GB 的内存,更何况微服务可以实现应用模块解耦(decoupling)。
PS:现在大家使用的 Web 服务器应该大多数是 Nginx,Nginx 正是支持负载均衡、反向代理、多服务器配置等,非常适合微服务和多主机部署。而 Apache 的模式是使用许多 httpd 的守护进程(daemons) 去响应页面请求。
将一个单一应用拆分为多个 microservice;将一台高配置的服务器改完多态小型服务器,即 agent。接着便可以使用 Kubnentes 管理集群。而为了管理多台服务器、多个服务实例,Kubernentes 提供了各种各样的组件。
在 Kubernetes 中,在每台小型服务器上的部署的应用,我们称 microservice(逻辑上) 或 agent(等同于一台服务器),应用的生命周期都是短暂(transient),因为一旦出现异常,都可能被替换掉。为了使用集群中的多个 microservice,我们需要服务和 API 调用。一个服务需要连接到另一个服务,则需要 agent 跟 agent 之间通讯,例如 Web 需要连接到 数据库。 Kubernetes 和 Consul 都有服务发现和网络代理或组网的功能,Kubernetes 提供了 kube-proxy ,Consul 提供了 Consul connect ,读者可以单独查阅资料了解。
读者可以点击下面的链接了解更多 Components of Kubernetes 的知识:
https://www.vmware.com/topics/glossary/content/components-kubernetes
Kubernetes Architecture
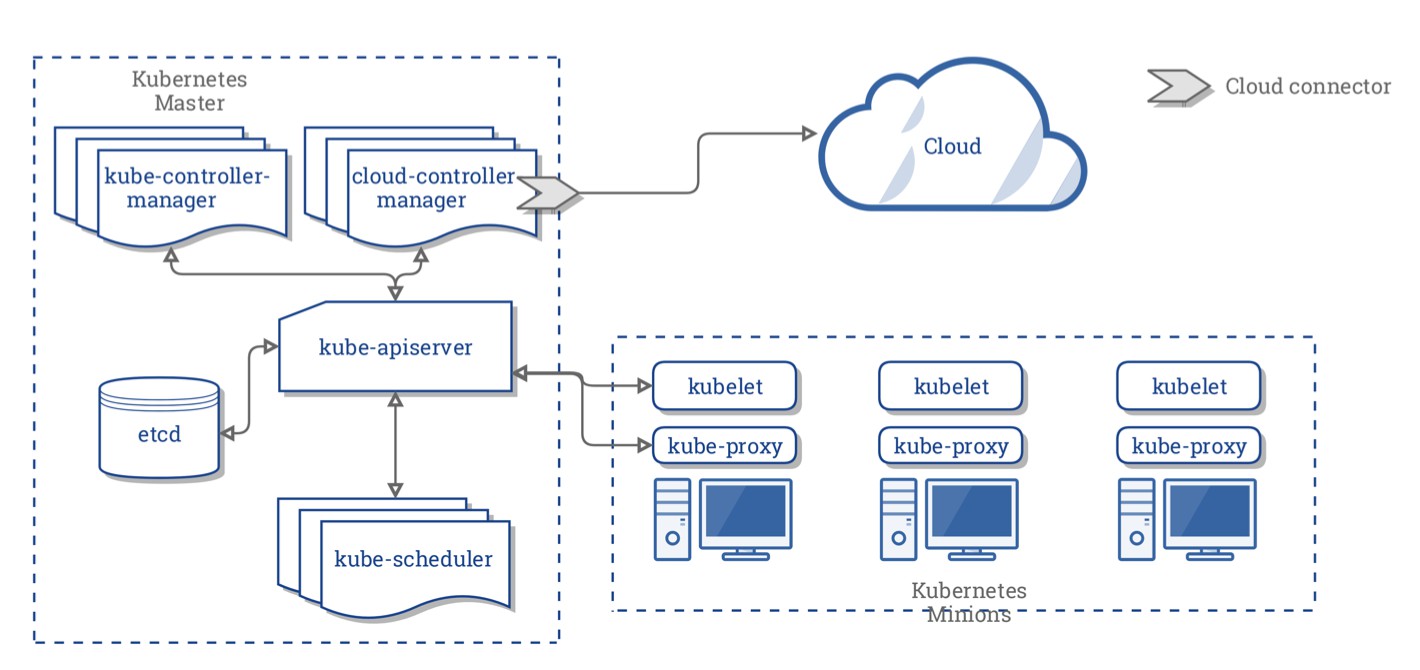
上图是简单的 kubernetes 结构,左侧虚线方框中,称为 central manager (也叫master) ,意思是中心(central)管理器;而右侧是三个工作节点(worker node),这些节点被称为 minions 。这两部分对应为 Master-Minions。
在 上图中, Master 由多个组件构成:
- 一个 API 服务(kube-apiserver)
- 一个调度器(kube-scheduler)
- 各种各样的控制器(上图有两个控制器)
- 一个存储系统(这个组件称为etcd),存储集群的状态、容器的设置、网络配置等书籍
接下来我们将围绕这张图片,去学习那些 Kubernetes 中的术语和关键字。
Docker cgroup And namespace
我们知道,操作系统是以一个进程为单位进行资源调度的,现代操作系统为进程设置了资源边界,每个进程使用自己的内存区域等,进程之间不会出现内存混用。Linux 内核中,有 cgroups 和 namespaces 可以为进程定义边界,使得进程彼此隔离。
namespace
在容器中,当我们使用 top 命令或 ps 命令查看机器的进程时,可以看到进程的 Pid,每个进程一个 Pid,而机器的所有容器都具有一个 Pid = 1 的基础,但是为什么不会发生冲突?容器中的进程可以任意使用所有端口,而不同容器可以使用相同的端口,为什么不会发生冲突?这些都是命名空间可以设定边界的表现。
Linux 中,unshare 可以创建一个命名空间(实际上是一个进程,命名空间中的其它进程是这个进程的子进程),并且创建一些资源(子进程)。为了深刻理解 Docker 中的 namespace,我们可以在 Linux 中执行:
sudo unshare --fork --pid --mount-proc bash然后执行 ps aux 查看进程:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 23612 3556 pts/1 S 21:14 0:00 bash
root 13 0.0 0.1 37624 3056 pts/1 R+ 21:14 0:00 ps aux是不是跟 Docker 容器执行命令的结果相似?我们还可以使用 nsenter 命令进入另一个进程的命名空间。
上面的代码中,--pid 参数代码创建 pid 命名空间,但是因为并没有隔离网络,因此当我们执行 netstat --tlap 命令时,这个命名空间的网络跟其它命名空间的网络还不是隔离的。
Linux 中的 namespace 类型有:
- mount :命名空间具有独立的挂载文件系统;
- ipc:Inter-Process Communication (进程间通讯)命名空间,具有独立的信号量、共享内存等;
- uts:命名空间具有独立的 hostname 、domainname;
- net:独立的网络,例如每个 docker 容器都有一个虚拟网卡;
- pid:独立的进程空间,空间中的进程 Pid 都从 1 开始;
- user:命名空间中有独立的用户体系,例如 Docker 中的 root 跟主机的用户不一样;
- cgroup:独立的用户分组;
Docker 中的命名空间正是依赖 Linux 内核实现的。
cgroups
cgroups 可以限制进程可使用的内存、CPU大小。cgroups 全称是 Control Groups,是 Linux 内核中的物理资源隔离机制。
为了避免篇幅过大,读者只需要知道 Docker 限制容器资源使用量、CPU 核数等操作,其原理是 Linux 内核中的 cgroups 即可,笔者这里不再赘述。
kube-apiserver
Kubernetes 通过 kube-apiserver 暴露一组 API,我们可以通过这些 API 控制 Kubernetes 的行为,而 kubernetes 有一个调用了这些 API 的本地客户端,名为 kubectl。当然,我们也可以利用这些 API 开发出跟 kubectl 一样强大的工具,例如网格管理工具 istio。
kube-scheduler
当要运行容器时,发送的请求会被调度器(kube-scheduler)转发到 API;调度器还可以寻找一个合适的节点运行这个容器。
node
集群中的每个节点都会运行着两个进程,分别是 kubelet,kube-proxy。(可以留意上图的 Kubernetes Mimons 里面)
在前面,我们知道当要运行一个容器时,需要调度器转发 API,这个请求最终会发送到 node 上的 kubelet,kubelet 可以接收 ”运行容器“ 的请求;kubelet 还可以管理那些必需的资源以及在本地节点上监控它们。
kube-proxy 可以创建和管理网络规则,以便在网络上公开容器。
Kubernetes Master 只能是 Linux,而 node 则可以是 Linux 和 Windows 等。
Terminology
本章将介绍一些 Kubenetes 的术语,以便提前了解 kubernetes 中的一些概念。本小节的内容并不会有太多解释,因为每部分要讲起来会很复杂,而这些在后面的 Kubernetes 技术中,都会单独讲解到,因此这里只是介绍一些简明的概念。读者不需要仔细看,只需要概览一遍即可。
Orchestration is managed
编排管理(Orchestration is managed) 是通过一系列的 监控循环(watch-loops)去控制或操作的;每个控制器(controller interogates) 都向 kube-apiserver 询问对象状态,然后修改它,直至达到条件。
容器编排是管理容器的最主要的技术。Dockers 也有其官方开发的 swarm 这个编排工具,但是在 2017 年的容器编排大战中,swarm 败于 Kubernetes。
namespace
Kubernetes 文档说,对于只有几到几十个用户的集群,根本不需要创建或考虑名字空间。这里我们只需要知道,集群资源被使用名字划出来,资源之间可以隔离开,这种名字称为命名空间。当然这个命名空间跟前面提到的 Linux 内核的命名空间技术不同,读者只需要了解到两者的理念相通就行。
Pod
Pod 是 Kubernetes 中创建和管理的、最小的可部署的计算单元。
在前面的学习中,我们已经了解到 Kubernetes 是一个编排系统(orchestration system),用于部署(deploy)和管理容器。而容器,在 一个 Pod 上运行,一个 Pod 运行着多个 容器,并且这些容器共享着 IP 地址、访问存储系统和命名空间。Kubernetes 通过命名空间让集群中的对象相互隔离开,实现资源控制和多租户(multi-tenant)连接。
Replication Controller
Replication Controller 简称 RC,应答控制器(Replication Controller) 用来部署和升级 Pod。
ReplicaSet
ReplicaSet 的目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。
如果 Pod 挂了,我们可以手工重启 Pod,但是这种操作方法肯定不靠谱,不可能人力 24 小时以及瞬时执行完一系列命令。
Deployments
Deployment 提供了一种对 Pod 和 ReplicaSet 的管理方式。这里不赘述,以后需要时再提及。
Kubernetes 对象
kubernetes 对象是持久化的实体,通过这些实体,可以雕塑整个集群的状态。这里介绍一些对象信息的表示。
- 对象名称和 IDs:使用名称、UID来表示其在同类资源中的唯一性;
- 命名空间:即之前提到的 namespace;
- 标签和选择算符:标签(Labels) 是附加到 Kubernetes 对象(比如 Pods)上的键值对;
- 注解:为对象附加的非标识的元数据;
- 字段选择器:根据一个或多个资源字段的值 筛选 Kubernetes 资源;
到此这篇关于Kubernetes(K8S)入门基础内容的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持编程学习网。